Пошаговый пайплайн для SEO-специалиста: откуда брать данные, как их чистить и группировать с помощью ИИ — и где нейросеть вас подведёт.
Большинство материалов про нейросети и семантику сводятся к одному: «вот промпт — вот результат». За кадром остаётся главное — откуда брать данные, как их готовить, как проверять вывод модели и когда ИИ просто не справится.
Этот гайд устроен как пошаговый пайплайн. Читайте последовательно или переходите к нужному разделу.
Как искусственный интеллект ускоряет сбор семантического ядра и обработку поисковых запросов
Стандартный процесс сбора семантики выглядит так: парсим Яндекс Вордстат, получаем таблицу на тысячи строк, потом часами вручную чистим мусор и раскладываем запросы по смыслу. Нейросети не отменяют этот процесс — они сжимают его самые трудоёмкие части.
Главное отличие ИИ от классических инструментов — он работает со смыслом, а не с буквами. Key Collector умеет собирать запросы и фильтровать по стоп-словам, но не понимает, что «купить диван в спб» и «диваны спб цены» — один и тот же интент, а «диван угловой фото» — уже другой. Именно здесь языковая модель выигрывает.
| Параметр | Классические инструменты | Нейросеть |
|---|---|---|
| Парсинг частотностей | ✓ Из источника | ✗ Не умеет |
| Очистка от мусора | Частично, по стоп-словам | ✓ По смыслу, гибко |
| Группировка по интенту | ✗ Нет | ✓ Основная сила |
| Скорость обработки 1 000 запросов | 30–60 мин вручную | 2–5 минут |
| Предложение структуры сайта | ✗ Нет | ✓ На основе кластеров |
| Актуальность данных | ✓ Реальная статистика | ✗ Не знает свежих цифр |
ИИ и классический инструментарий не конкурируют — они дополняют друг друга. Парсер даёт сырой массив с реальными частотностями. Нейросеть превращает этот массив в структуру: быстро, без ручного перебора строк. Весь пайплайн ниже построен на этой связке.

Где взять данные для нейросети: парсинг Яндекс Вордстат и очистка сырого списка от мусора
Нейросеть не ходит в Яндекс Вордстат за вас. Она не знает частотности запросов и не умеет парсить конкурентов самостоятельно. Всё, что модель делает — анализирует список, который вы ей передаёте. Поэтому качество входных данных напрямую определяет качество результата.
Откуда берём сырой список
Лучший вариант — комбинировать несколько источников:
- Яндекс Вордстат — базовый источник для рунета. Парсим через Key Collector или Словоёб, выгружаем в CSV с частотностями.
- Google Search Console — реальные запросы, по которым сайт уже получает показы. Незаменимо для расширения существующего ядра.
- Анализ конкурентов — через Semrush, Ahrefs или SpyWords. Находит запросы, которые вы пропустили при парсинге.
- Подсказки поисковых систем — автодополнение Яндекса и Google даёт длинный хвост с чёткими интентами.
Передавайте в нейросеть только текст запросов — без частотностей, регионов и прочих столбцов таблицы. Данные о частотах оставьте рядом в Excel: они понадобятся на этапе проверки результата.
Минимальная подготовка перед подачей в ИИ
Типичный список после парсинга — это смесь полезных запросов, брендов конкурентов, информационного мусора и дублей. Подавать всё это без подготовки — значит получить кластеры с примесями, которые потом придётся чистить вручную.
- Удалите явный мусор: нечитаемые строки, технические артефакты парсинга, явные опечатки.
- Уберите бренды конкурентов, которые вам не нужны.
- Сделайте базовую дедупликацию в Excel — функция «Удалить дубликаты» уберёт точные совпадения.
- Разбейте список на блоки по 300–500 запросов: большинство моделей хуже справляются с очень длинными промптами.
Промпт для очистки списка ключевых слов
Вот что не работает — и почему:
Вот список ключевых слов. Убери ненужные. [список запросов]
Модель не знает, что считать «ненужным» для вашего проекта. Без контекста она действует наугад — и удаляет нужные запросы, оставляя мусор.
Рабочий промпт даёт модели контекст проекта, чёткие критерии и ожидаемый формат вывода:
Ты — SEO-специалист. Я дам тебе список поисковых запросов для интернет-магазина мягкой мебели (диваны, кресла, пуфы). Магазин работает только по России, не продаёт бренды IKEA, Hoff, Lazurit. Твоя задача — очистить список. Удали: 1. Запросы с названиями конкурентных брендов (IKEA, Hoff, Lazurit и подобные). 2. Информационный мусор, не связанный с покупкой или выбором мебели — например, «история дивана», «как починить пружину». 3. Смысловые дубли — оставь один вариант из пары («диван купить» и «купить диван» — оставь более естественно звучащий). 4. Запросы с опечатками, которые не являются вариантами реального написания. Формат ответа: верни только очищенный список — по одному запросу на строке, без комментариев. Список запросов: [вставьте сюда 300–500 запросов]
~40% запросов в сыром списке после парсинга Вордстата — это мусор: бренды конкурентов, нерелевантные хвосты и смысловые дубли. Хороший промпт на очистку убирает их за пару минут вместо часов ручной работы.
Что передаём вместе со списком
Чем точнее контекст — тем лучше результат. В промпт на очистку всегда включайте эти четыре вещи:
Что продаёте или о чём пишете. Одно-два предложения.
Список конкурентов, запросы с которыми нужно удалить.
Регион работы, если это влияет на релевантность запросов.
Укажите явно: список, таблица или JSON.
После очистки у вас будет компактный, смыслово однородный массив запросов. Именно с ним мы будем работать дальше — группировать по интенту, строить кластеры и формировать структуру сайта.

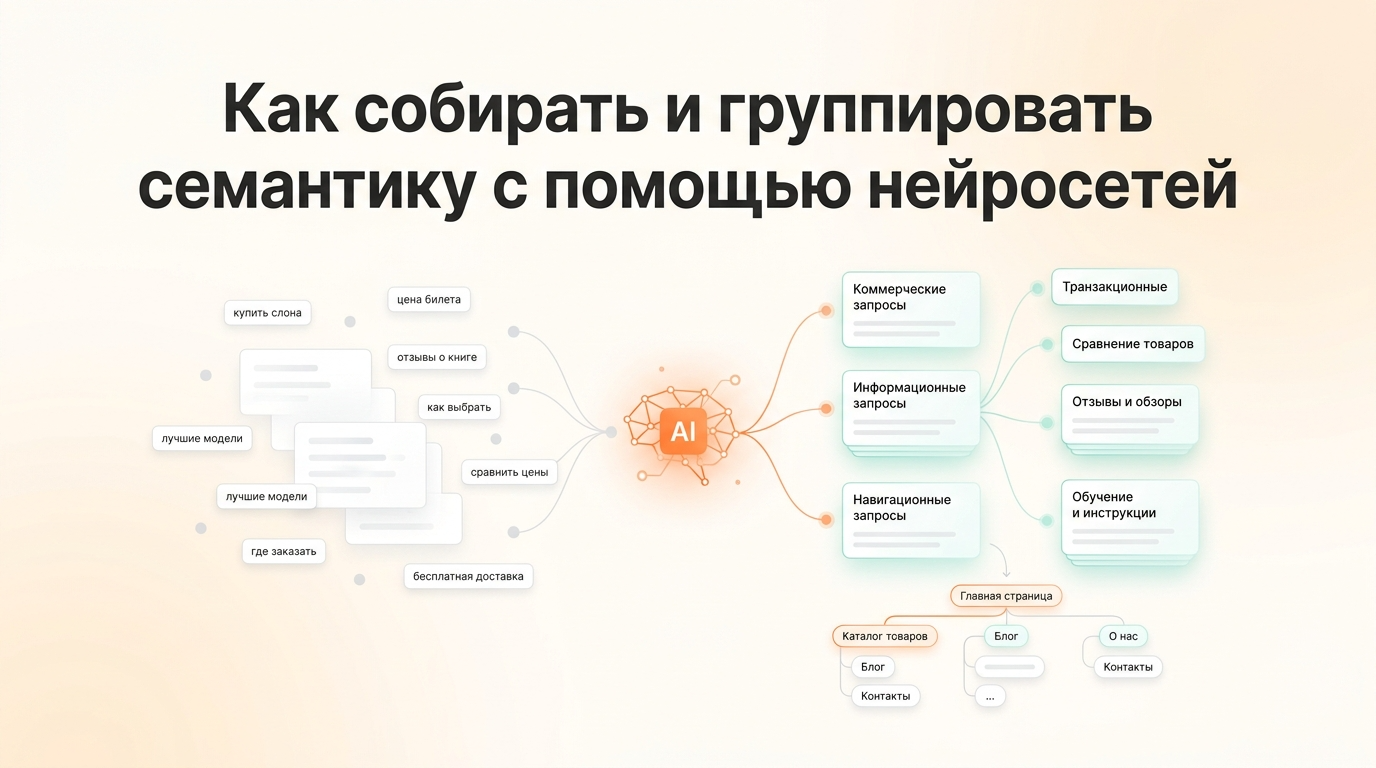
Как использовать ИИ для выявления намерений: делим запросы на информационные и коммерческие
Раньше SEO-специалисты группировали запросы по словам: все фразы со словом «купить» — в одну кучу, со словом «как» — в другую. Это работало на простых нишах, но давало сбои там, где один и тот же запрос мог означать разное. «Диван раскладной» — человек хочет купить или просто посмотреть варианты? Классический инструмент не ответит. Нейросеть — ответит.
ИИ понимает смысл запроса в контексте, а не просто ищет знакомые слова. Именно это делает его незаменимым на этапе разбивки семантики по интентам — намерениям пользователя.
Четыре типа интентов, которые важно различать
- Информационные — человек хочет узнать: «как выбрать диван», «чем отличается велюр от рогожки».
- Коммерческие (исследовательские) — человек сравнивает варианты перед покупкой: «лучшие диваны 2024», «диван vs кресло-кровать».
- Транзакционные — человек готов купить прямо сейчас: «купить диван угловой недорого», «заказать диван с доставкой».
- Навигационные — человек ищет конкретный сайт или бренд: «hoff каталог диванов», «диваны официальный сайт».
Смешивать запросы с разными интентами на одной странице — распространённая ошибка. Страница, которая пытается одновременно продавать и обучать, как правило, плохо ранжируется по обоим типам запросов. ИИ помогает эту проблему решить до того, как вы начали создавать контент.
Промпт для базовой сортировки по интентам
Ты — SEO-аналитик. Я дам тебе список поисковых запросов. Раздели каждый запрос по типу намерения пользователя: — Информационный (хочет узнать, разобраться) — Коммерческий (сравнивает, выбирает) — Транзакционный (готов купить) — Навигационный (ищет конкретный сайт или бренд) Формат ответа — таблица с двумя столбцами: «Запрос» и «Интент». Без пояснений. Список запросов: [вставьте список]
Если список большой и вы хотите сразу отфильтровать только нужные интенты — используйте более точный промпт:
Из списка поисковых запросов ниже выбери только транзакционные — те, где пользователь явно намерен купить, заказать или оформить услугу. Остальные запросы не включай в ответ. Формат: список запросов, по одному на строке. Список: [вставьте список]
Пример: как ИИ разделяет похожие запросы
Возьмём три похожих запроса из ниши мебели:
| Запрос | Интент | Какая страница нужна |
|---|---|---|
| как выбрать угловой диван | Информационный | Статья в блоге или гайд |
| угловые диваны фото цены | Коммерческий | Категория каталога |
| купить угловой диван недорого | Транзакционный | Посадочная страница с фильтром по цене |
Без разделения по интентам все три запроса легко попадают на одну страницу — и она не закрывает ни один из них в полной мере. После сортировки становится понятно: здесь нужны три разные страницы с разной структурой и разным контентом.

Пошаговый гайд по кластеризации запросов: как сгруппировать семантику для посадочных страниц
Кластеризация — это следующий шаг после сортировки по интентам. Здесь задача другая: сгруппировать запросы так, чтобы каждая группа стала основой для одной страницы сайта. Тысяча ключевых слов превращается в 40–60 чётких кластеров, каждый из которых отвечает на конкретный запрос конкретного пользователя.
Главная угроза на этом этапе — каннибализация. Это ситуация, когда несколько страниц сайта конкурируют между собой за одни и те же ключевые слова. Поисковая система не знает, какую из них показывать, и в итоге не показывает ни одну нормально. Правильная кластеризация исключает эту проблему заранее.
Как устроен процесс кластеризации с помощью ИИ
- Берём очищенный список запросов одного интента — например, только транзакционные.
- Передаём его нейросети с задачей: сгруппировать по теме так, чтобы запросы внутри одной группы логично жили на одной странице.
- Просим модель дать каждому кластеру название — оно станет рабочим заголовком страницы.
- Проверяем результат: нет ли запросов, которые попали сразу в два кластера.
- Сопоставляем кластеры с частотностями из Excel — отсеиваем группы с нулевым трафиком.
Промпт для кластеризации семантического ядра
Ты — SEO-стратег. Я дам тебе список поисковых запросов для интернет-магазина мягкой мебели. Все запросы — транзакционные (пользователь хочет купить). Твоя задача: 1. Сгруппируй запросы в кластеры. В каждом кластере — запросы, которые логично закрывает одна посадочная страница. 2. Дай каждому кластеру короткое название (будущий H1 страницы). 3. Убедись, что каждый запрос входит только в один кластер — дублирования быть не должно. 4. Если запрос не подходит ни к одному кластеру — вынеси его в отдельную группу «Не распределено». Формат ответа: Кластер: [Название] — запрос 1 — запрос 2 — запрос 3 Список запросов: [вставьте список]
Результат работы модели будет выглядеть примерно так:
| Кластер | Запросы в группе | Тип страницы |
|---|---|---|
| Угловые диваны | купить угловой диван, угловой диван недорого, угловой диван с доставкой | Категория каталога |
| Диваны-кровати | диван кровать купить, диван трансформер цена, раскладной диван заказать | Категория каталога |
| Детские диваны | диван для детской комнаты, маленький диван для ребёнка купить | Подкатегория |
| Не распределено | диван бу, мягкая мебель б/у | Решение вручную |
Группу «Не распределено» не игнорируйте. Там часто оказываются запросы с неожиданным интентом — например, аудитория, которую вы не планировали охватывать, но которая реально ищет ваш продукт.

Как находить низкочастотные запросы и расширять кластеры с помощью длинных хвостов
После кластеризации основного списка часто оказывается, что кластеры получились тонкими — по 3–5 запросов на страницу. Это нормально: Вордстат фиксирует только то, что люди ищут достаточно часто. Но реальный поиск намного богаче. Люди задают вопросы в голосовом поиске, пишут длинные фразы, формулируют запросы так, как никакой парсер не предскажет.
Здесь нейросеть даёт то, чего классические инструменты дать не могут — она генерирует варианты запросов, опираясь на понимание темы, а не на статистику частотности.
LSI и Long-tail: в чём разница
Тематически связанные слова и фразы, которые помогают поисковику понять контекст страницы. Пример: для страницы про угловые диваны — «обивка», «наполнитель», «механизм трансформации».
Длинные конкретные фразы с низкой частотностью, но высокой точностью интента. Пример: «угловой диван с независимым пружинным блоком до 40000 рублей».
Long-tail запросы конвертируются лучше, потому что человек уже принял решение. Конкуренция по ним ниже. И именно их сложнее всего найти через парсинг — зато легко сгенерировать через ИИ.
Промпт для генерации LSI-запросов
Я создаю страницу каталога для интернет-магазина мебели по теме: «Угловые диваны». Сгенерируй 20 LSI-фраз и тематических слов, которые стоит использовать в тексте этой страницы. Это должны быть слова и словосочетания, которые семантически связаны с темой и помогут поисковику понять контекст. Формат: список фраз, по одной на строке. Без нумерации и пояснений.
Промпт для генерации long-tail запросов
Ты — SEO-специалист. Я веду интернет-магазин мягкой мебели. Мне нужно расширить кластер запросов для страницы «Угловые диваны». Сгенерируй 25 низкочастотных поисковых запросов — длинных, конкретных, с явным намерением купить. Включай уточнения по размеру, материалу, цене, способу доставки, типу механизма. Имитируй то, как реальный человек набирает запрос в поисковике. Формат: список запросов, по одному на строке.
70% всех поисковых запросов — низкочастотные. Большинство из них никогда не попадут в Вордстат, но трафик по ним суммарно превышает высокочастотные ключевые слова. ИИ позволяет находить этот пласт без дополнительных инструментов.
Запросы, которые сгенерировала нейросеть, обязательно проверяйте в Яндекс Вордстат. Часть из них окажется нулевой — это нормально. Но среди них регулярно встречаются реальные фразы с живым трафиком, которые вы бы никогда не нашли вручную.
Как создать логичную структуру сайта и навигацию на основе собранного семантического ядра
Когда кластеры готовы, перед вами фактически уже есть скелет сайта. Осталось превратить таблицу с группами запросов в дерево страниц: категории, подкатегории, фильтры, статьи блога. Именно это SEO-специалисты называют архитектурой сайта — и именно здесь ошибки обходятся дороже всего, потому что переделывать структуру после запуска болезненно.
ИИ на этом этапе работает как архитектор: берёт список кластеров и предлагает, как их иерархически организовать. Он не знает технических ограничений вашей CMS, но отлично видит логические связи между темами.
Кейс: структура интернет-магазина мебели из кластеров
Допустим, после кластеризации у нас 48 групп запросов. ИИ помогает выстроить из них трёхуровневую структуру:
| Уровень | Страница | Источник |
|---|---|---|
| Главная | Интернет-магазин мягкой мебели | Высокочастотные транзакционные |
| Категория | Диваны / Кресла / Пуфы | Крупные кластеры по типу товара |
| Подкатегория | Угловые диваны / Диваны-кровати / Детские диваны | Средние кластеры с уточнением |
| Фильтр / тег | Диваны до 30 000 рублей / Диваны с доставкой за 1 день | Long-tail кластеры с параметрами |
| Блог | Как выбрать диван / Чем отличается велюр от рогожки | Информационные кластеры |
Такой подход к SEO-продвижению сайта исключает хаотичное создание страниц. Каждая новая страница появляется потому, что под неё есть кластер с реальным спросом — а не потому, что так захотел маркетолог.
Промпт для проектирования структуры сайта
Ты — SEO-архитектор. Я дам тебе список кластеров семантического ядра для интернет-магазина мягкой мебели. Каждый кластер — это группа поисковых запросов с названием. Твоя задача — предложить иерархическую структуру сайта на основе этих кластеров: 1. Распредели кластеры по уровням: главная → категории → подкатегории → фильтры/теги → блог. 2. Если несколько кластеров логично объединяются в одну категорию — объедини. 3. Укажи предлагаемый URL-slug для каждой страницы (латиницей). 4. Отдельно выдели кластеры, которые лучше реализовать как статьи блога, а не как страницы каталога. Формат ответа: [Уровень] Название страницы | /url-slug → [Уровень] Подстраница | /url-slug/podstranitsa Список кластеров: [вставьте список кластеров с названиями]
Попросите модель дополнительно отметить страницы, которые могут конкурировать между собой — это ещё один способ поймать потенциальную каннибализацию до начала работ.
3 уровня — оптимальная глубина структуры для большинства интернет-магазинов с точки зрения SEO. Страницы глубже четвёртого уровня получают значительно меньше веса от поисковых систем.

Примеры работы с ИИ: кластеризация для интернет-магазинов, сайтов услуг и контентных проектов
Промпт для кластеризации — не универсальный. То, что работает для магазина, даст плохой результат для агентства или блога. Тип сайта определяет, как формулировать задачу, какие интенты приоритетны и как выглядит итоговая структура. Разберём три основных сценария.
Приоритет — транзакционные запросы. Кластеры = категории и подкатегории каталога. Важно учитывать фильтры: по цене, цвету, материалу. Информационные запросы идут в блог.
Смешанный интент: часть запросов коммерческие («заказать», «стоимость»), часть — информационные («как происходит», «что входит»). Кластеры = отдельные услуги + FAQ-страницы.
Почти все запросы информационные. Кластеры = темы статей. Важно группировать по рубрикам, а не по отдельным материалам — иначе статьи будут конкурировать друг с другом.
Как адаптировать промпт под каждый тип
Для интернет-магазина в промпте делайте акцент на структуре каталога:
Учитывай, что сайт — интернет-магазин. Каждый кластер должен соответствовать одной странице каталога или подкатегории. Запросы с параметрами (цена, цвет, размер) выдели в отдельные кластеры для страниц фильтров.
Для сайта услуг важно разделить «продающие» страницы и вспомогательные:
Сайт оказывает услуги (ремонт квартир). Раздели кластеры на два типа: коммерческие страницы услуг (пользователь хочет заказать) и информационные страницы (пользователь хочет разобраться в теме). Для каждого кластера укажи тип страницы.
Для блога задача — не допустить пересечения тем между статьями:
Сайт — информационный блог. Сгруппируй запросы в кластеры так, чтобы каждый кластер закрывала одна статья. Убедись, что темы кластеров не пересекаются — запросы из одной статьи не должны попасть в поисковой выдаче на другую.
Небольшое дополнение в промпте полностью меняет логику группировки. Модель начинает смотреть на запросы через призму вашего бизнеса — и результат становится намного ближе к тому, что можно сразу передавать в работу.

Почему ручной анализ и классические SEO-инструменты всё ещё необходимы для проверки данных
Нейросети действительно сильно ускоряют работу с семантикой, но у них есть фундаментальное ограничение: они не имеют доступа к реальным данным поисковых систем. Модели генерируют ответы на основе статистических закономерностей из обученных текстов, а не на основе актуальной информации о поисковом спросе, алгоритмах ранжирования и поведении пользователей. Из-за этого при работе с семантикой возникают серьёзные риски.
Три типичные ошибки ИИ при работе с семантикой
- Выдуманные частотности. Если попросить нейросеть указать частотность запроса, она почти всегда называет какое-то число. Уверенно и без оговорок. Это чистая галлюцинация. ИИ не подключён к Яндекс Wordstat, Google и никогда не имел актуальных данных о спросе.
- Путаница микро-интентов. Модель часто объединяет запросы, которые выглядят похоже, но имеют совершенно разное намерение пользователя. Например, «диван купить» и «диван своими руками» могут попасть в один кластер. На больших списках такие ошибки встречаются регулярно и сильно снижают эффективность продвижения.
- Несуществующие запросы. При генерации long-tail фраз нейросеть нередко придумывает запросы, которые звучат правдоподобно, но никогда не вводились людьми в поиск. Такие ключи выглядят привлекательно, но дают нулевой трафик и бесполезны для стратегии.
Важное правило: никогда не просите у нейросети данные о частотности запросов. Любое число, которое она называет — это галлюцинация. Для получения реальных данных используйте только Яндекс Wordstat, Key Collector, Serpstat или другие инструменты с прямым доступом к поисковым системам.
Дополнительные риски использования ИИ
Кроме трёх основных ошибок, есть ещё несколько скрытых проблем. Нейросети плохо учитывают сезонность, региональные особенности (например, разницу спроса в Москве и регионах), изменения в алгоритмах поисковых систем и фактор E-E-A-T. Также они не видят актуальную картину SERP — какие типы страниц сейчас ранжируются в топ-10 по нужным запросам.
Как правильно проверять результат работы нейросети
На проверку одного среднего проекта обычно уходит 20–40 минут. Этого достаточно, чтобы значительно повысить качество семантического ядра:
- Сопоставление с частотностями. Выбираете 10–15 ключей из каждого кластера и проверяете их в Wordstat. Кластеры с преимущественно нулевой или очень низкой частотностью требуют пересмотра.
- Анализ SERP. Ручная проверка топ-10 по 3–5 ключам из кластера. Если поисковая выдача показывает совсем другой тип страниц — модель ошиблась с определением интента.
- Оценка коммерческой привлекательности. Проверяете, насколько запросы в кластере соответствуют вашим товарам/услугам и способны приносить продажи.
- Контроль каннибализации. Убеждаетесь, что один запрос не попал в несколько разных кластеров.
~15–20% кластеров в среднем требуют ручной корректировки после работы нейросети. Это нормальный показатель. Главное — не пропустить эти случаи, потому что даже 5–7% ошибок могут заметно снизить общую эффективность продвижения.
Современные алгоритмы поисковых систем становятся всё сложнее. Они учитывают не только точное вхождение ключей, но и релевантность содержания, пользовательский опыт, поведенческие факторы и доверие к сайту. Именно поэтому финальная экспертная оценка специалиста остаётся критически важной.
ИИ отлично справляется с рутинными задачами и убирает до 80% монотонной работы. Однако оставшиеся 20% — это экспертная оценка, глубокое понимание бизнеса, проверка данных и стратегическое мышление. Связка «нейросеть + опытный SEO-специалист» сегодня даёт значительно лучшие результаты, чем использование только одного из этих инструментов.
Где взять готовые промпты для работы с семантическим ядром: коллекция от BestpromptAI
Все промпты из этого гайда — рабочие. Но каждый раз адаптировать их под новый проект вручную — это время. Именно для этого в BestpromptAI собраны категории: готовые шаблоны с заполненными переменными, которые можно использовать сразу — без правок и без опыта в промптинге.
Промпты для удаления мусора, брендов конкурентов и смысловых дублей под разные ниши.
Шаблоны для разделения запросов на информационные, коммерческие и транзакционные.
Готовые промпты для e-commerce, услуг и блогов — каждый заточен под свой тип сайта.
Шаблон для превращения кластеров в иерархию страниц с URL-slug и типом контента.
Каждый шаблон в коллекции устроен одинаково: вверху — входной формат (что вставить), внутри — готовый промпт, внизу — пример вывода. Вы просто подставляете свои данные и запускаете в ChatGPT, Claude или любой другой модели.
Промпты в библиотеке подходят как для SEO-специалистов, которые хотят автоматизировать рутину, так и для владельцев сайтов, которые впервые берутся за семантику самостоятельно. Никакого специального опыта работы с ИИ не нужно.
Готовые промпты для кластеризации семантики — в одном месте
Промпты в BestpromptAI. Открывайте шаблон, вставляйте данные, получайте результат.
Использовать готовые промпты в BestpromptAI →
FAQ: секреты кластеризации и оптимизации семантики через нейросети
Можно ли полностью заменить Key Collector нейросетью при сборе семантики?
Нет — и это принципиально важно понимать. Key Collector и аналогичные сервисы (Serpstat, Rush Analytics) парсят реальные частотности из Яндекс Wordstat, оценивают сезонность, коммерциализацию выдачи и собирают поисковые подсказки. Нейросеть этого делать не умеет: у неё нет прямого доступа к актуальным базам данных поисковых систем.
Правильная и наиболее эффективная схема — это гибридный подход. Парсер выполняет роль «шахтёра», собирая сырой массив данных с точными цифрами и метриками конкуренции. Нейросеть выступает в роли «аналитика», проводя первичную очистку, кластеризацию и глубокий анализ интентов. Инструменты решают абсолютно разные задачи: классический софт отвечает за математику, а ИИ — за смысловую логику.
Какие нейросети лучше подходят для кластеризации семантического ядра — ChatGPT, Claude или другие?
Сегодня все ведущие языковые модели хорошо справляются с этой рутиной, но на практике их сильные стороны различаются:
- Claude (семейство Sonnet) — лучший выбор для больших списков ключей. Он имеет огромное окно контекста, феноменально держит логику на длинных промптах и лучше других понимает нюансы русской морфологии.
- ChatGPT (GPT-4o) — идеален для работы со сложным форматированием. Если вам нужно получить результат в виде строгой Markdown-таблицы, CSV-файла для импорта в Excel или JSON — GPT справится точнее. Также он лучше фильтрует коммерческий спам.
- Grok, Gemini и локальные модели — показывают хорошие результаты при генерации идей (например, сбор long-tail и LSI-фраз), но могут «плыть» при строгой кластеризации тысяч строк.
Выбор модели вторичен. Гораздо важнее качество промпта и использование платных тарифов (или API), так как бесплатные версии сильно обрезают контекст и начинают галлюцинировать уже на 200-м запросе.
Сколько запросов можно передавать нейросети за один раз при кластеризации?
Оптимальный объём для стабильного результата — 300–500 запросов на один промпт. При большем количестве срабатывает эффект «деградации внимания» (attention loss): языковая модель начинает игнорировать инструкции, пропускает ключи в середине списка или хаотично объединяет несвязанные группы.
При работе с крупным семантическим ядром (от 5 000 ключей) категорически рекомендуется разбивать список на узкие тематические блоки. Сначала выделите все ключи со словом «угловые», отдайте их ИИ. Затем переходите к «прямым». Это сохраняет кристальную чистоту кластеризации и сводит ручную доработку к минимуму.
Как проверить, что нейросеть не выдумала запросы при генерации long-tail семантики?
Единственный надёжный метод верификации — массовая проверка сгенерированного списка через Key Collector или Яндекс Wordstat (обязательно в кавычках `""`, чтобы отсечь мусор). Если точная частотность равна нулю — запрос выдуман.
Однако не спешите удалять нулевые ключи. Даже если 50% сгенерированных фраз окажутся «пустышками» для прямого трафика, они служат мощнейшей базой LSI-слов. Вплетение таких микрочастотных смысловых конструкций в текст делает статью максимально релевантной и экспертной в глазах алгоритмов Яндекса и Google (улучшение факторов E-E-A-T).
Что такое каннибализация запросов и как нейросеть помогает её избежать?
Каннибализация — это критическая SEO-ошибка, при которой две или более страниц вашего сайта пытаются ранжироваться по одним и тем же ключевым словам. В результате поисковые роботы не могут определить приоритетную посадочную страницу (URL), вес рассеивается, а позиции проседают.
ИИ блокирует эту проблему на корне. Правильно составленный промпт заставляет нейросеть строить жёсткую матрицу релевантности: каждый ключ жестко привязывается только к одному кластеру и одному H1. Вы получаете карту сайта без смысловых пересечений ещё до того, как копирайтер напишет первое слово.
Можно ли использовать нейросети для анализа семантики конкурентов?
Да, поиск упущенной семантики (Content Gap) — один из самых мощных юзкейсов ИИ в SEO. Нейросеть не выгрузит данные сама, но она блестяще анализирует готовые Excel-файлы, экспортированные из Ahrefs, Serpstat или Keys.so.
Сценарий прост: выгружаете ключи трех главных конкурентов из ТОП-10, объединяете их со своим ядром и пишете промпт: «Сравни списки и выдели кластеры, которые приносят трафик конкурентам, но полностью отсутствуют в моем ядре». Это экономит часы сверки таблиц через функцию ВПР.
Как организовать сбор и хранение семантики, если работаю один без команды?
Для соло-специалиста критически важен порядок в данных. Самая масштабируемая архитектура выглядит так:
- Google Таблицы — единый центр управления.
- Изолированные вкладки: «Сырой парсинг» (оригинал), «Очищенный пул», «Сводная кластеризация», «Карта структуры URL», «Мусор/Минус-слова».
- Цветовое кодирование: зеленым помечаются согласованные кластеры, желтым — спорные интенты, требующие ручной сверки SERP.
- База промптов: все рабочие инструкции обязательно сохраняйте в BestpromptAI, Notion или Obsidian, чтобы не изобретать велосипед для каждого нового проекта.
Безопасно ли передавать данные о семантике и структуре сайта в нейросеть?
Сами по себе поисковые ключи — это публично доступная информация. Передавать сырую семантику в ChatGPT или Claude абсолютно безопасно, так как любой ваш конкурент может спарсить те же самые фразы за пару часов.
Риск возникает, если вы скармливаете ИИ коммерческую тайну: внутренние показатели конверсии (CR), данные о продажах конкретных товарных матриц или списки email-адресов клиентов. Если используете коммерческие цифры для аналитики, предварительно анонимизируйте их. Для параноидальной безопасности используйте API-подключения — по умолчанию платформы не обучают свои алгоритмы на данных, переданных через API.
Как часто нужно обновлять семантическое ядро сайта?
Частота зависит от волатильности ниши. В динамичных сферах (маркетплейсы, электроника, крипта, инфобизнес) микро-интенты и модели поиска меняются постоянно. Здесь ядро нужно пересматривать каждые 3–4 месяца. В консервативных B2B нишах (производство бетона, аренда спецтехники) достаточно одной глубокой пересборки в год.
Главный триггер для внепланового аудита семантики — резкое падение органического трафика при сохранении позиций. Это значит, что алгоритмы поиска изменили интент выдачи, и ваши страницы больше не отвечают ожиданиям целевой аудитории.
Как интегрировать работу с нейросетями в общую стратегию SEO-продвижения?
Искусственный интеллект должен забирать рутину, освобождая мозг специалиста для стратегии. Идеальный пайплайн: ИИ делает черновую очистку, кластеризацию, собирает LSI-хвосты и формирует карту редиректов.
Высвобожденные часы SEO-эксперт инвестирует в те задачи, где машина бессильна: качественный линкбилдинг (построение ссылочного профиля), технический краулинг, анализ коммерческих факторов доверия, A/B тестирование сниппетов и улучшение юзабилити (UX). Автоматизация процессов — это не замена SEO-шника, это мультипликатор его эффективности.
Можно ли с помощью ИИ оптимизировать Title, Description и мета-теги?
Да, массовая генерация мета-тегов — одна из сильнейших сторон нейросетей. Если у вас 500 карточек товаров, писать Title руками экономически невыгодно. Достаточно задать жесткий промпт.
Обязательно укажите лимиты (Title до 70 символов, Description до 160), попросите включить главный маркерный запрос ближе к началу, использовать CTR-триггеры («в наличии», «доставка 0₽», «гарантия») и добавить спецсимволы. Модель сгенерирует идеальные, кликабельные теги в виде таблицы, готовой для импорта в любую CMS.
Как сочетать нейросети с настройкой контекстной рекламы (Яндекс Директ)?
Семантика, отфильтрованная нейросетью, идеально ложится в основу рекламных кампаний. Но главная суперсила ИИ здесь — это работа с минус-словами. Вы можете загрузить сырой массив и дать команду: «Вытащи все некоммерческие слова, топонимы чужих регионов и названия брендов конкурентов».
За пару минут вы получите исчерпывающий список минус-фраз для кросс-минусовки. Кроме того, собранные long-tail кластеры отлично работают в стратегии низкочастотного трафика: они повышают показатель качества объявлений и кардинально снижают цену за клик (CPC), увеличивая рентабельность маркетингового бюджета.
Какие главные ошибки допускают новички при использовании ИИ в SEO?
Самая фатальная ошибка — делегирование 100% ответственности алгоритму без этапа валидации. Новички слепо верят кластерам ИИ, не открывая реальную выдачу (SERP), и в итоге создают страницы, которые Яндекс отказывается ранжировать из-за несовпадения типа контента.
Вторая ошибка — скудные, «ленивые» промпты (вида «сгруппируй ключи»). Без указания региона, специфики бизнеса, списка исключений и описания целевой аудитории нейросеть выдаст усредненный, шаблонный мусор. Третья — игнорирование классических SEO-метрик в угоду скорости.
Нужно ли обновлять свои рабочие промпты со временем?
Обязательно. Языковые модели постоянно обновляются, их алгоритмы становятся умнее и понимают более сложный контекст. Промпт, который вы использовали для GPT-3.5 год назад, сегодня морально устарел.
Кроме того, меняются требования самих поисковиков. Сегодня Яндекс и Google уделяют колоссальное внимание интентному соответствию и экспертности. Регулярно пересматривайте свою библиотеку запросов: добавляйте новые переменные, усложняйте логику, тестируйте формат системных инструкций (System Instructions) и создавайте кастомных GPT-ассистентов под узкие задачи вашего агентства.